remote collaboration with kinect
Prototype built during 6-month internship at
NTT Media Innovation Laboratory in Yokosuka, Japan

Here I am remotely collaborating in Blender with my colleagues at Cinegrid UCSD -- from my seat in Japan.
- Role: Research, design, implementation
- Tools: JavaScript, HTML, CSS, Kinect SDK, C#, Visual Basic, OSC messages, WebRTC, node.js
- Deliverable: Working prototype; paper published in IEICE Technical Report; presented paper at Kyoto conference
introduction
From July to December 2014, I worked in the Media Innovation Laboratory at NTT. While I spent the first few months absorbing the research agenda and tools of my lab-mates working on API design for the Remote Collaboration Open Platform (REMOCOP), I eventually zeroed in on a problem mentioned by one of our clients (a major car manufacturer):
"4K telepresence and hi-fi remote collaboration are great, but we have offices and collaborators in India and elsewhere that don't have 24/7 access to high-bandwidth connections. How can we better collaborate with them?"
Research Questions
I focused the rest of my time at NTT on these questions (first through a series of rapid prototypes, and then through the longer-term prototype described on this page):
- Given that desktop remote collaboration software often relies on the ability to transfer high-
bandwidth data (e.g. video, screen sharing), we ask:(1) What is the useful information remote collaborators gain from a visual channel?
(2) Can we abstract this information, and find a way to transmit it without transmitting a full video signal?
Answers to (1) were determined from user interviews -- they were:
- The number of participating locations/devices
- The number of participants
- Who the participants are
- Who has the floor (i.e. who is speaking)
- Who wants the floor
- Other participants’ activities with respect to the collaborative context
- Other participants’ gestures, affective states, and other subtle, nonverbal cues
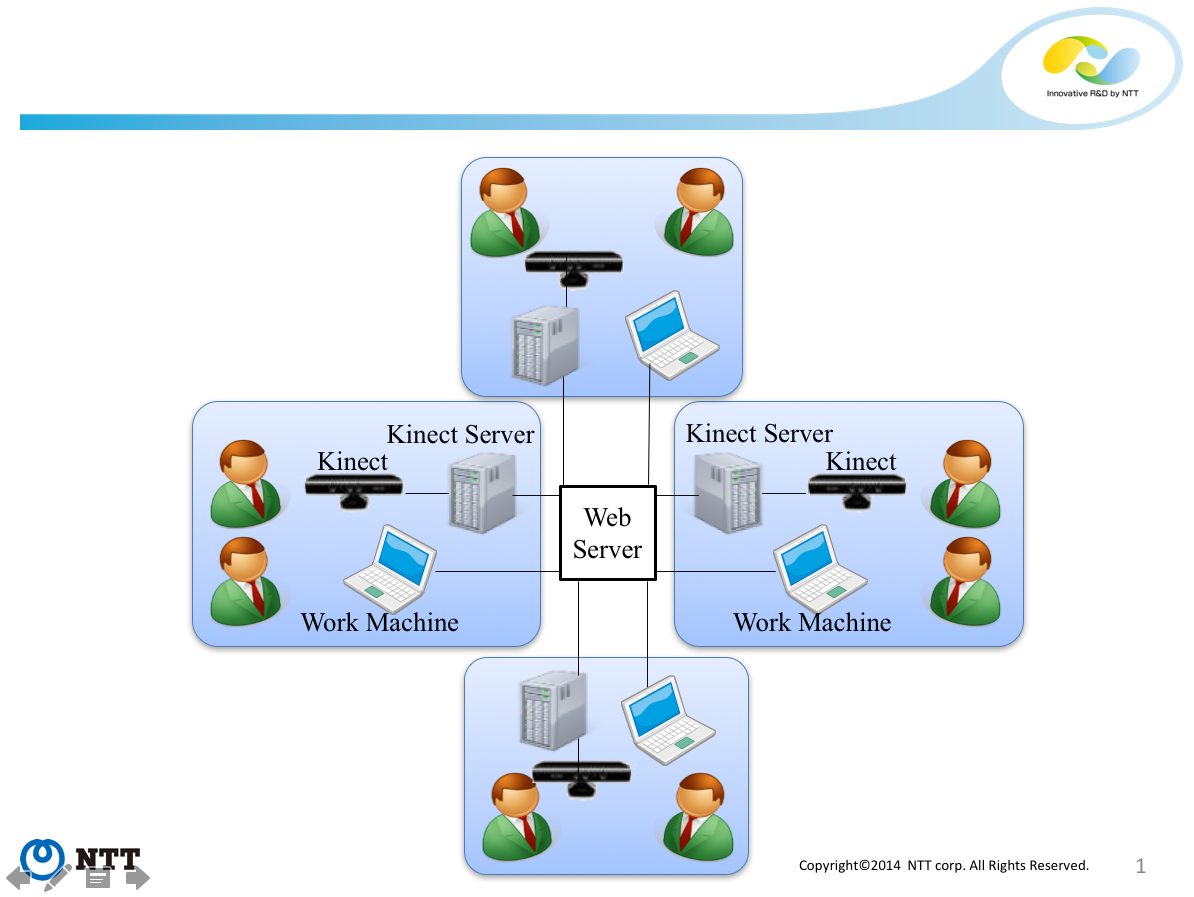
My prototype tracks these by using a Kinect as a sensor in each location.

what i made
I created a web application that receives data from a Kinect, such as the number of detected skeletons (i.e. point-and-line-based human body structures) and the physical position of detected skeletons in the Kinect’s field of view. The web app takes this information, transmits it as an OSC message via node.js, and displays it in a graphical interface to participants in a conference-call-type setting: for example, displaying at each location the number of participants present in each other location, and identifying information for each of the displayed participants. Lastly, and perhaps most usefully, when a participant speaks, the GUI indicates the identity of the current speaker.

The current speaker is highlighted (name, role, location) when Kinect detects (with directional microphone) that they are speaking.

Grid of remote participants on left, shared task on right.
I ran four rounds of user tests and interviews, collated the results in a six-page paper ("Sensor Data Visualization in Non-Video Remote Collaboration Situations") which was published in an IEICE Technical Report, and which I traveled to present at the SIS conference in Kyoto in December 2014.